|
I am particularly interested in the up-to-date combination of Multimodal Large Language Models with (1) Hallucination, Continual Instruction Tuning (2) Reliable Reasoning (3) Post Training Generalizability (4) Efficient Inference and so on.
👏
Welcome all forms of academic discussion and collaboration. Feel free to contact me!
Email📧: challengezengfh (at) gmail (dot) com /
Google Scholar /
Github /
LinkedIn
📣
I am currently available and looking for Internship opportunities for these directions. I would greatly appreciate it if you have any positions or suggestions!
News
-
[2026.02] One paper about post-training quantization (QIG) is accepted to CVPR 2026!!
-
[2025.09] One paper about model merging (RobustMerge) is accepted to NeurIPS 2025 as a Spotlight !!
-
[2025.08] One paper about multimodal continual instruction tuning (ModalPrompt) is accepted to EMNLP 2025!!
-
[2025.06] One paper about federated continual instruction tuning (FCIT) is accepted to ICCV 2025. Congratulations to all my collaborators!
-
[2025.05] Two papers about MLLMs (HiDe-LLaVA, ChartEdit) are accepted to ACL 2025. Congratulations to all my collaborators!
-
[2025.02] One paper about learned image compression (MambaIC) is accepted to CVPR 2025!!
-
[2025.01] One paper about out-of-distribution detection (Local-Prompt) is accepted to ICLR 2025.
|
Research Experience
-
Research Intern @ School of Computer Science, Peking University, China, 2025.03-2025.08
Advisor: Hao Tang
-
Research Intern @ Institute for Al Industry Research, Tsinghua University, China, 2024.05-2025.02
Advisor: Yan Wang
-
Research Intern @ Baidu, Inc., China, 2023.02-2024.01
Advisor: Deli Yu
|
Selected Publications [View All]
* indicates equal contribution
|
|
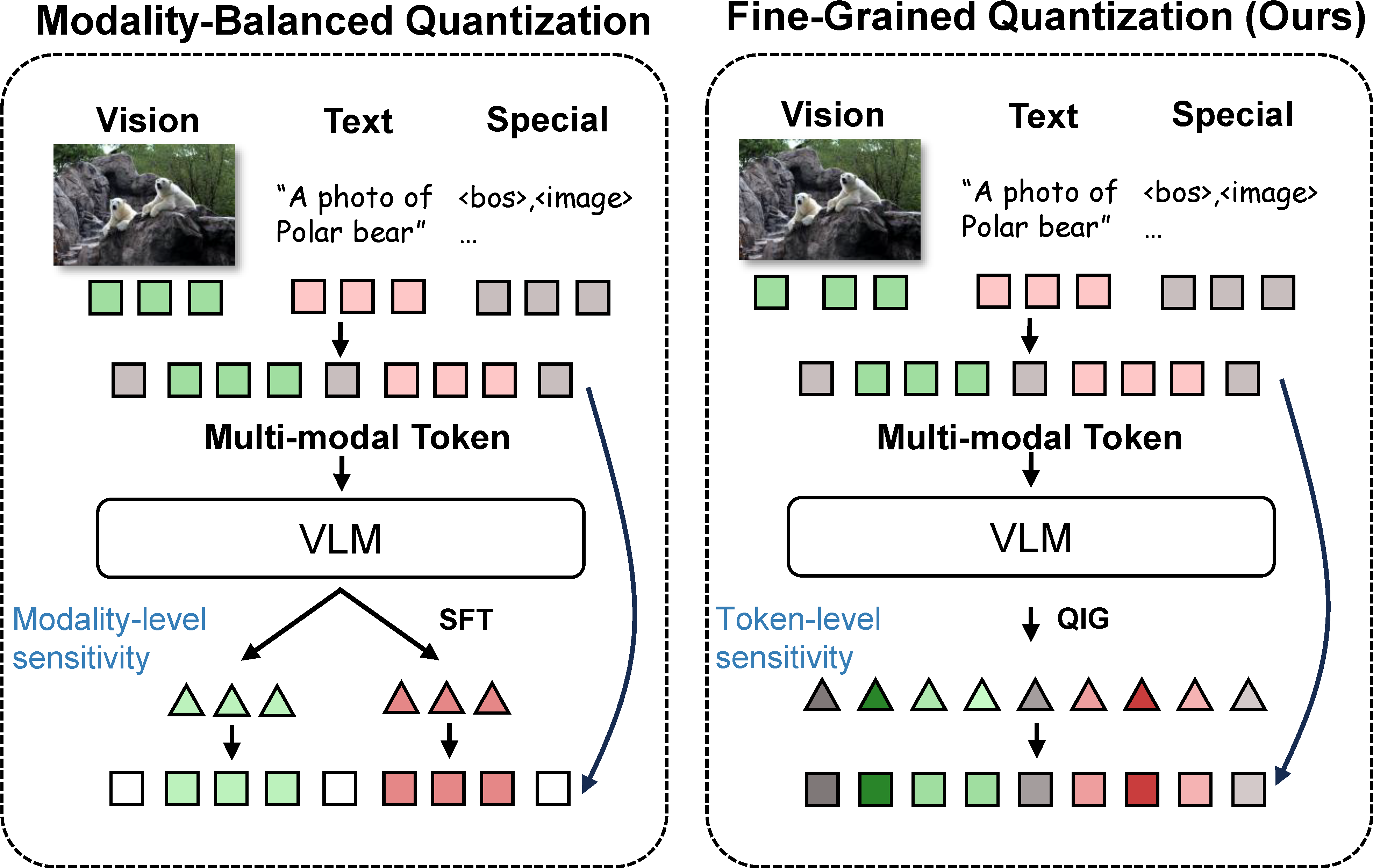
Fine-Grained Post-Training Quantization for LVLMs with Quantization-Aware Integrated Gradients
Ziwei Xiang*, Fanhu Zeng*, Hongjian Fang, Rui-Qi Wang, Renxing Chen, Yanan Zhu, yi chen, Peipei Yang, Xu-Yao Zhang
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
|
|
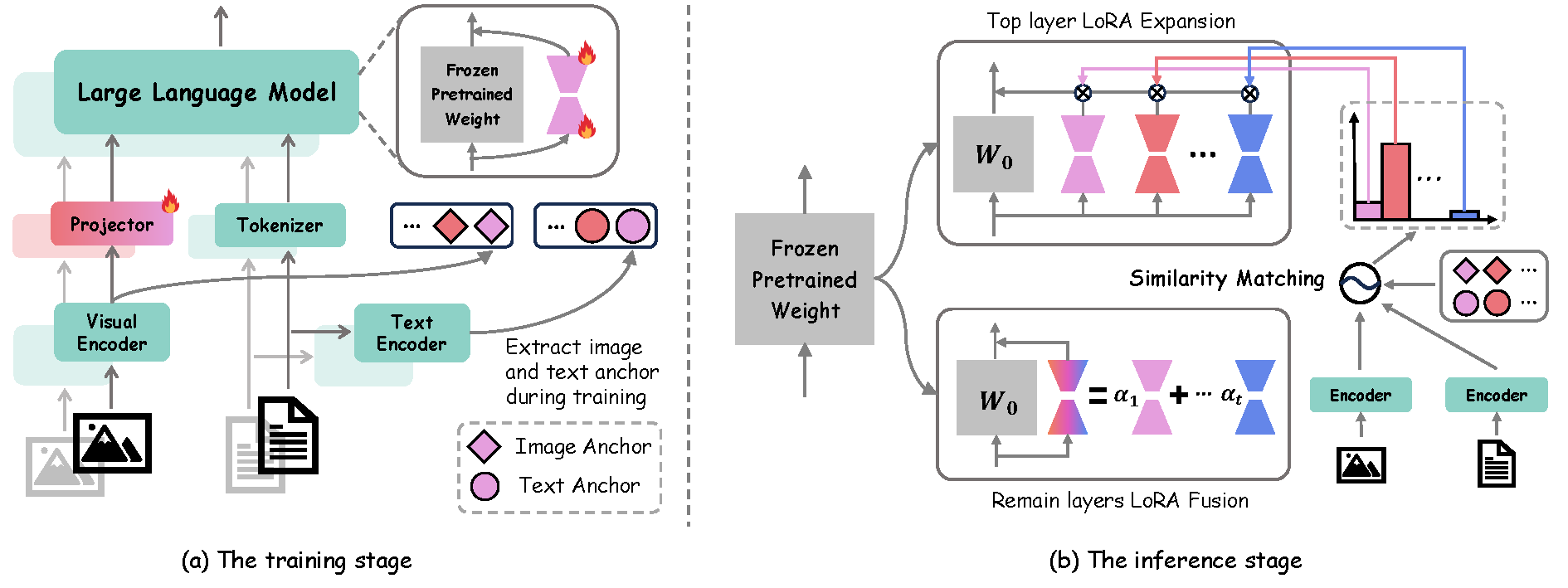
RobustMerge: Parameter-Efficient Model Merging for MLLMs with Direction Robustness
Fanhu Zeng, Haiyang Guo, Fei Zhu, Li Shen, Hao Tang
The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025, Spotlight, acceptance rate: 3.1%
|
|
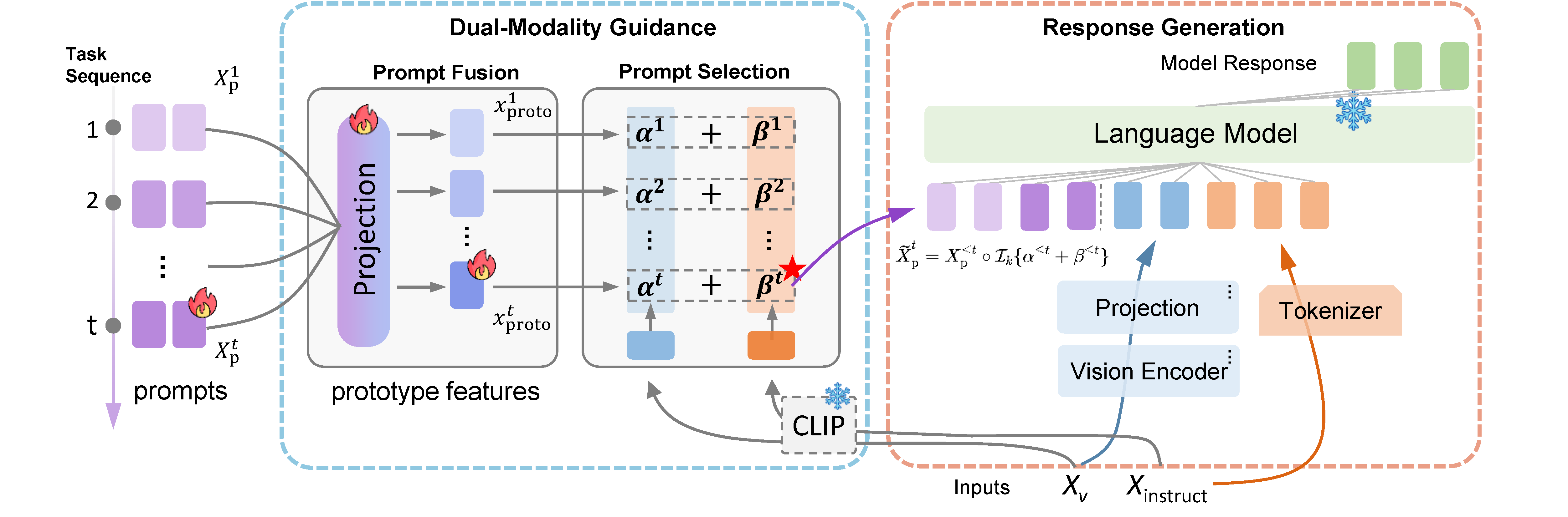
ModalPrompt: Towards Efficient Multimodal Continual Instruction Tuning with Dual-Modality Guided Prompt
Fanhu Zeng, Fei Zhu, Haiyang Guo, Xu-Yao Zhang, Cheng-Lin Liu
The 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025
|
|
HiDe-LLaVA: Hierarchical Decoupling for Continual Instruction Tuning of Multimodal Large Language Model
Haiyang Guo*, Fanhu Zeng*, Ziwei Xiang, Fei Zhu, Da-Han Wang, Xu-Yao Zhang, Cheng-Lin Liu
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025
|
|
MambaIC: State Space Models for High-Performance Learned Image Compression
Fanhu Zeng, Hao Tang, Yihua Shao, Siyu Chen, Ling Shao, Yan Wang
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
|
|
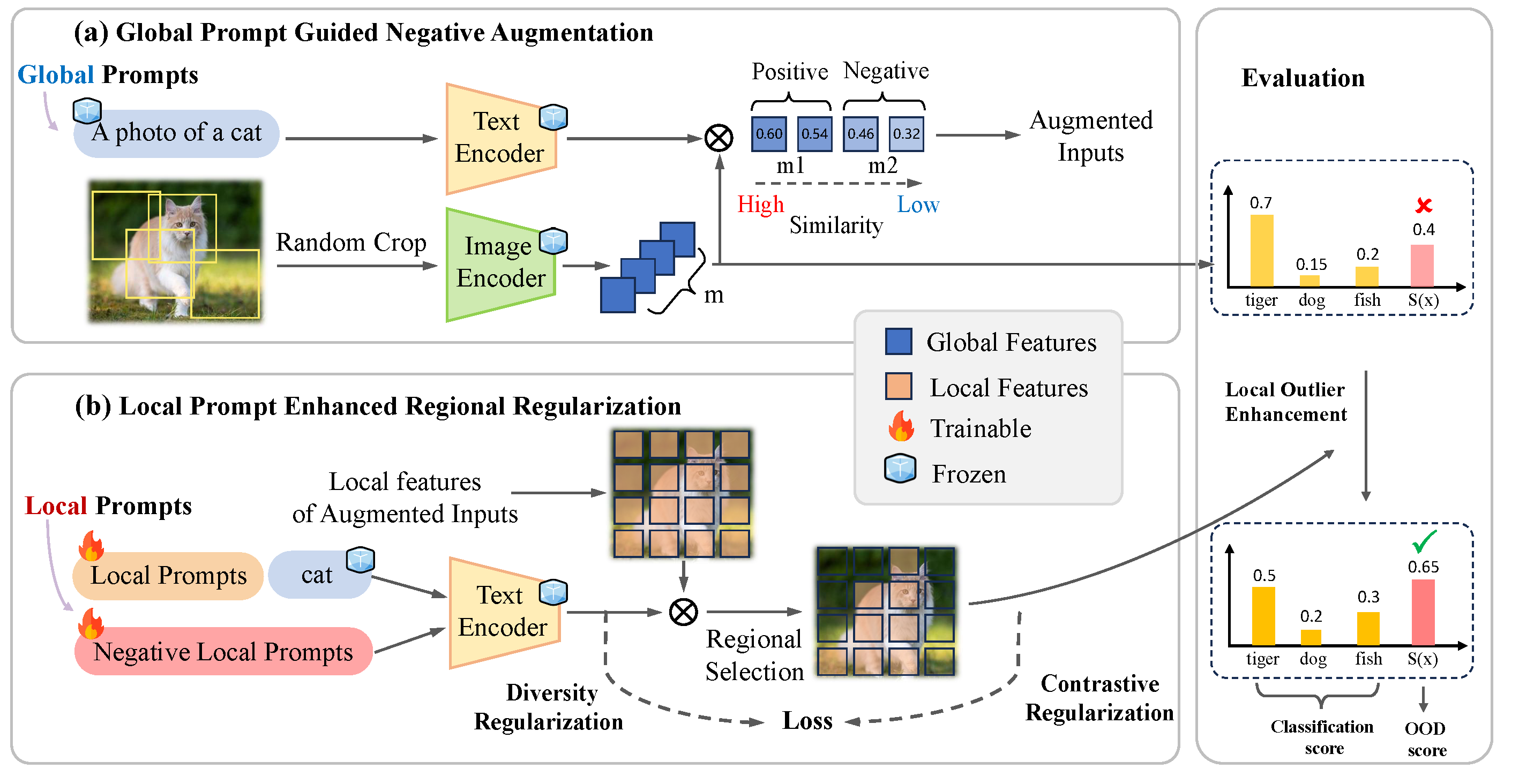
Local-Prompt: Extensible Local Prompts for Few-Shot Out-of-Distribution Detection
Fanhu Zeng, Zhen Cheng, Fei Zhu, Hongxin Wei, Xu-Yao Zhang
The Thirteenth International Conference on Learning Representations (ICLR), 2025
|
|
All Publications →
|
Academic Services
Conference Reviewer: NeurIPS (2024), ICLR (2025, 2026), ICML (2026), CVPR (2025, 2026), ICCV (2025), EMNLP (2023), BMVC (2026)
|
|
