Publications
* indicates equal contribution
| 2026 | |
|
TR-DQ: Time-Rotation Diffusion Quantization
Yihua Shao, Deyang Lin, Minxi Yan, Siyu Chen, Fanhu Zeng, Minwen Liao, Ao Ma, Ziyang Yan, Haozhe Wang, Yan Wang, Zhi Chen, Xiaofeng Cao, Haotong Qin, Hao Tang, Jingcai Guo
The 40th AAAI Conference on Artificial Intelligence (AAAI), 2026
|
| 2025 | |
|
RobustMerge: Parameter-Efficient Model Merging for MLLMs with Direction Robustness
Fanhu Zeng, Haiyang Guo, Fei Zhu, Li Shen, Hao Tang
The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025, Spotlight, acceptance rate: 3.1%
|
|
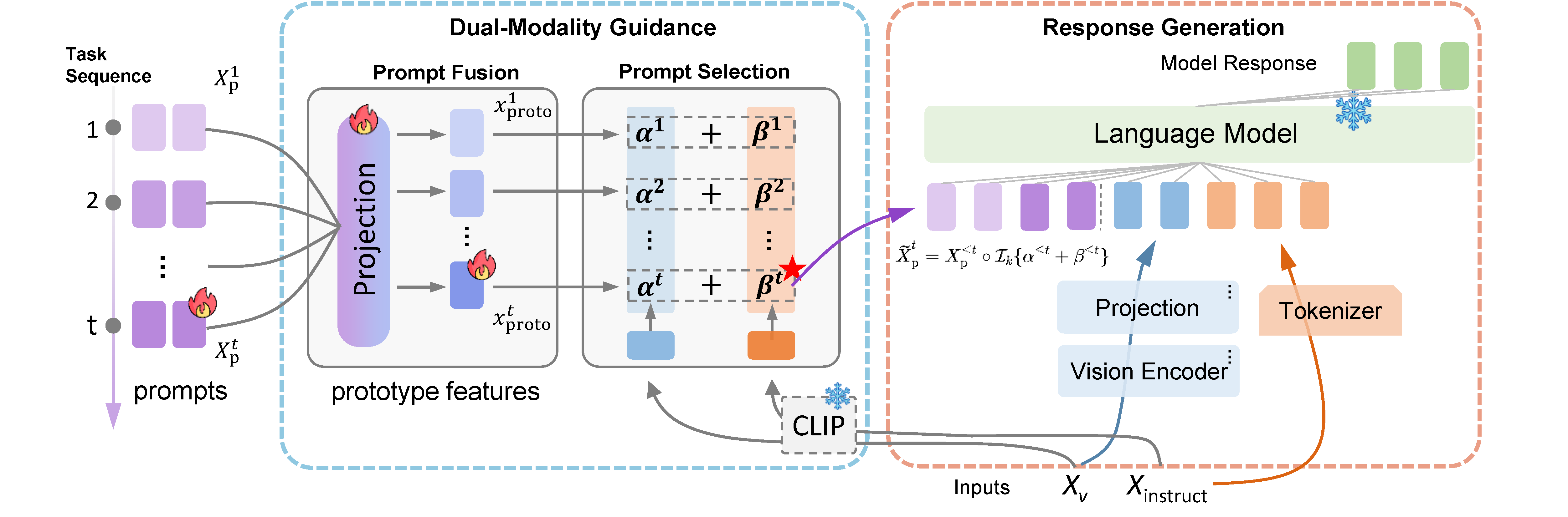
ModalPrompt: Towards Efficient Multimodal Continual Instruction Tuning with Dual-Modality Guided Prompt
Fanhu Zeng, Fei Zhu, Haiyang Guo, Xu-Yao Zhang, Cheng-Lin Liu
The 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025
|
|
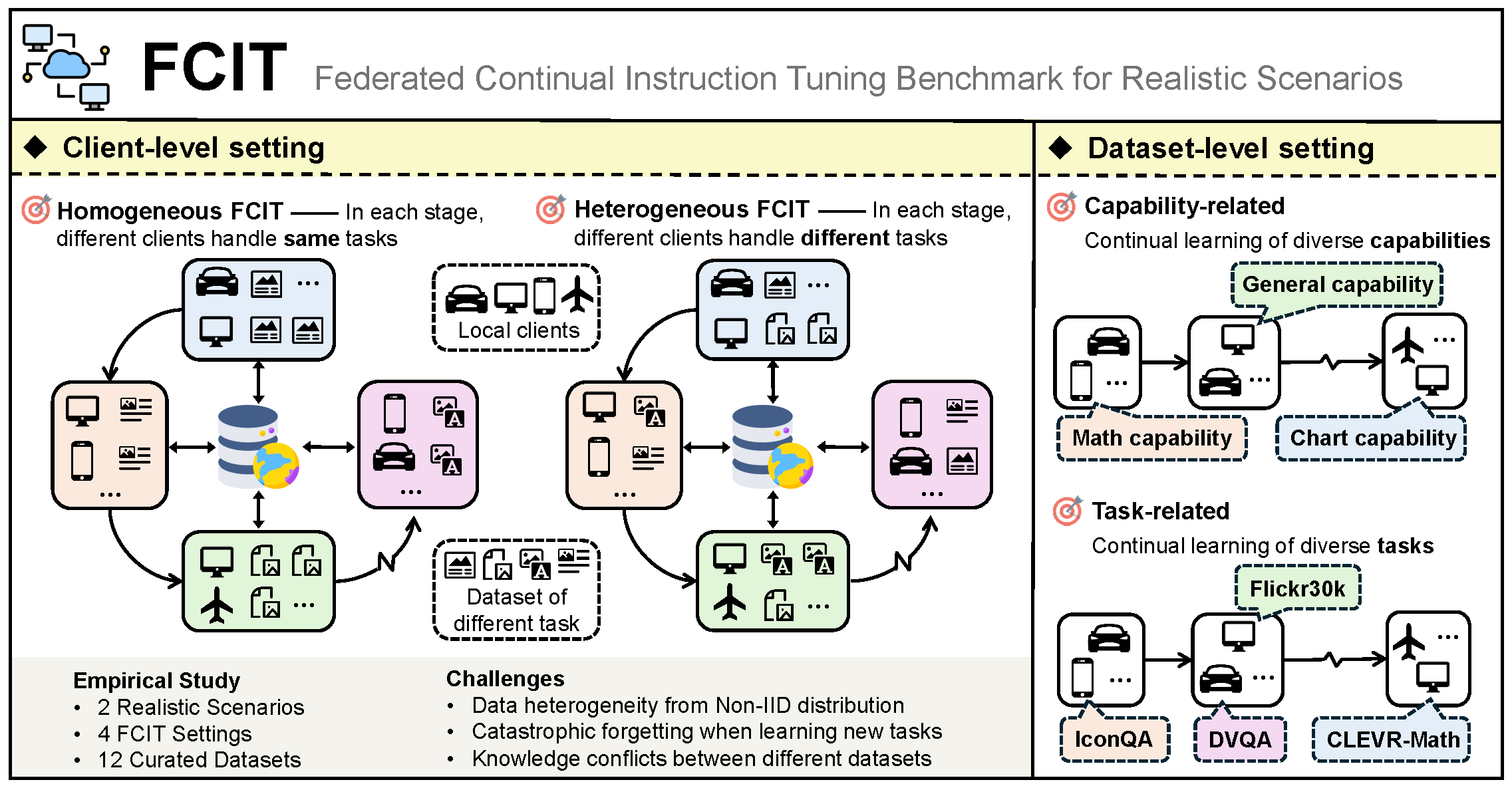
Federated Continual Instruction Tuning
Haiyang Guo, Fanhu Zeng, Fei Zhu, Wenzhuo Liu, Da-Han Wang, Jian Xu, Xu-Yao Zhang, Cheng-Lin Liu
International Conference on Computer Vision (ICCV), 2025
|
|
MCITlib: Multimodal Continual Instruction Tuning Library and Benchmark
Haiyang Guo, Fei Zhu, Hongbo Zhao, Fanhu Zeng, Wenzhuo Liu, Shijie Ma, Da-Han Wang, Xu-Yao Zhang
Workshop on Multimodal Continual Learning, International Conference on Computer Vision (ICCV), 2025, Oral
|
|
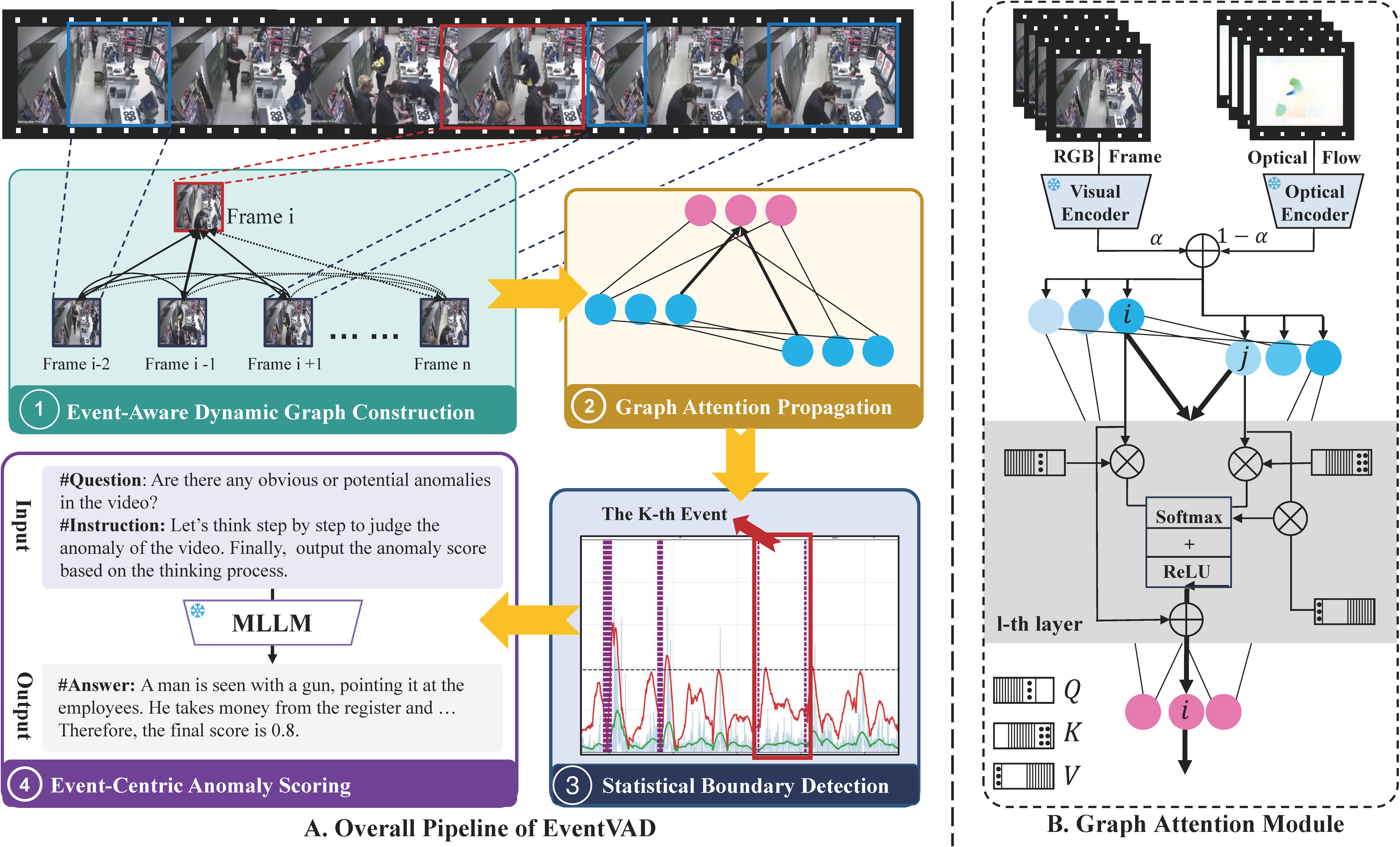
EventVAD: Training-Free Event-Aware Video Anomaly Detection
Yihua Shao, Haojin He, Sijie Li, Siyu Chen, Xinwei Long, Fanhu Zeng, Yuxuan Fan, Muyang Zhang, Ziyang Yan, Ao Ma, Xiaochen Wang, Hao Tang, Yan Wang, Shuyan Li
The 33rd ACM International Conference on Multimedia (ACM MM), 2025, Oral
|
|
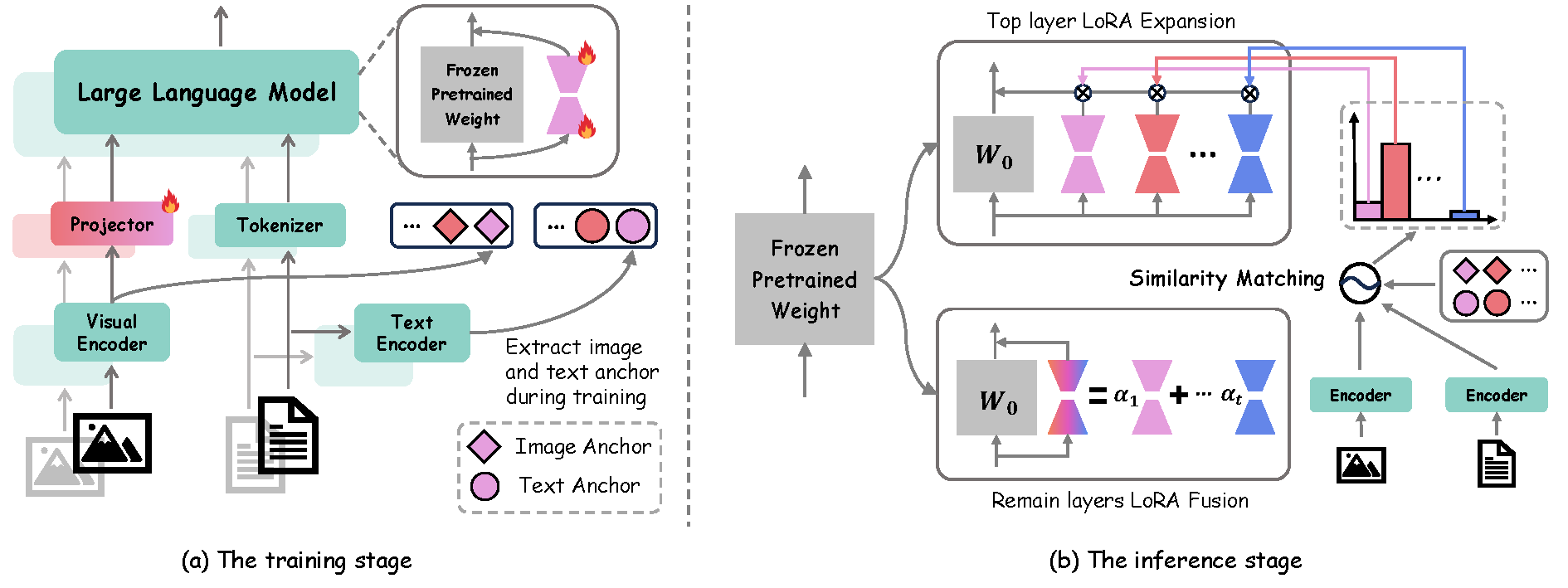
HiDe-LLaVA: Hierarchical Decoupling for Continual Instruction Tuning of Multimodal Large Language Model
Haiyang Guo*, Fanhu Zeng*, Ziwei Xiang, Fei Zhu, Da-Han Wang, Xu-Yao Zhang, Cheng-Lin Liu
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025
|
|
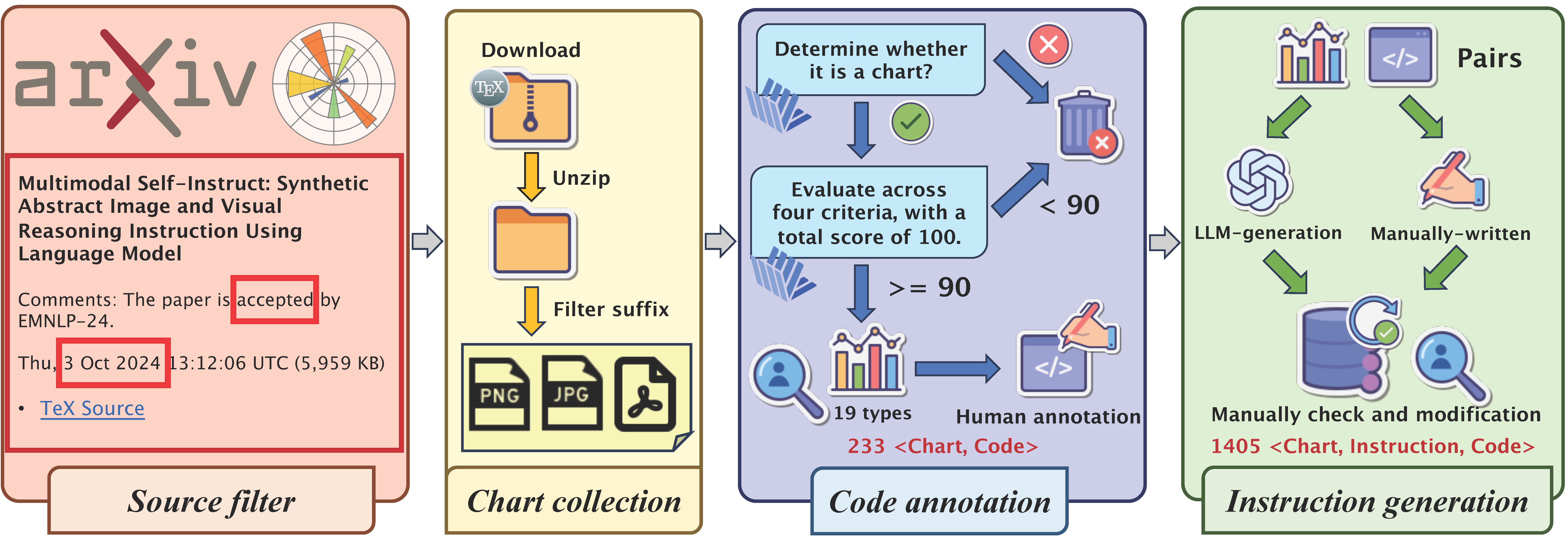
ChartEdit: How Far Are MLLMs From Automating Chart Analysis? Evaluating MLLMs’ Capability via Chart Editing
Xuanle Zhao*, Xuexin Liu*, Haoyue Yang*, Xianzhen Luo, Fanhu Zeng, Jianling Li, Qi Shi, Chi Chen
Findings of the Association for Computational Linguistics (ACL), 2025
|
|
MambaIC: State Space Models for High-Performance Learned Image Compression
Fanhu Zeng, Hao Tang, Yihua Shao, Siyu Chen, Ling Shao, Yan Wang
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
|
|
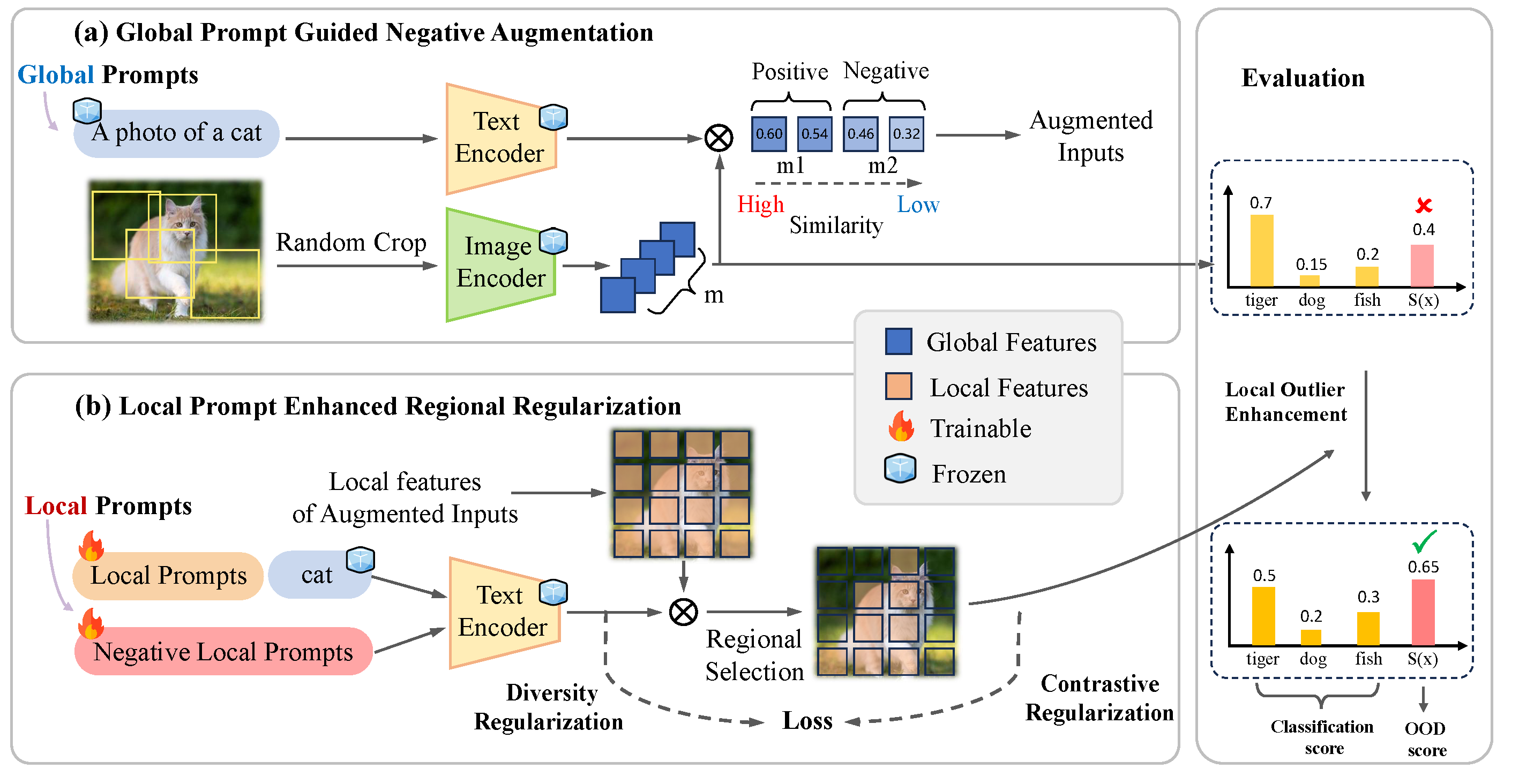
Local-Prompt: Extensible Local Prompts for Few-Shot Out-of-Distribution Detection
Fanhu Zeng, Zhen Cheng, Fei Zhu, Hongxin Wei, Xu-Yao Zhang
The Thirteenth International Conference on Learning Representations (ICLR), 2025
|
| 2024 | |
|
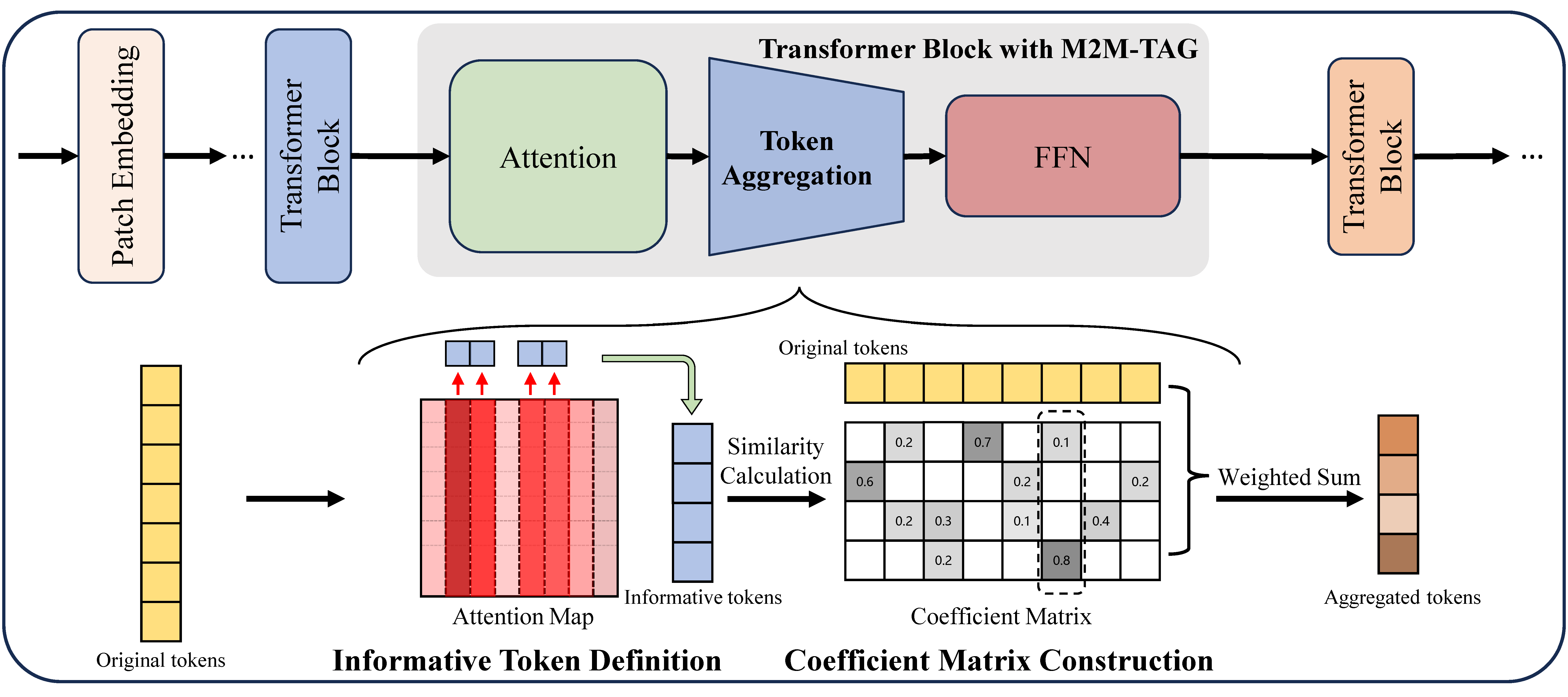
M2M-TAG: Training-Free Many-to-Many Token Aggregation for Vision Transformer Acceleration
Fanhu Zeng, Deli Yu
Workshop on Machine Learning and Compression, Neural Information Processing Systems (NeurIPS), 2024
|